
ServerlessArchitecture#06 Caching for Serverless Applications
Lambda auto-scales by traffic , but it has a limit


In one of my interview, I have been asked
"Is Caching still relevant for Serverless Applications?"
The Assumption
Lambda auto-scales by traffic, so do we still need to worry about caching? And if so, where and how do we implement caching?
To summarize, the blog Use-Cases are:
- Is Caching still relevant for Serverless Applications?
- Conflict To Resolve: Lambda auto-scales by traffic, so do we still need to worry about caching? Is it TRUE !!!
- Lambda auto-scales by Traffic but it has limits { soft limit: 1000 concurrent executions (VMs/instances), hard limit: after initial burst, 500 concurrent executions/min}
- Remember: Once that limit is reached, functions will scale at a rate of 500 instances per minute until they exhaust all available concurrency.
- When this 500/min limit could cause a problem? Check the predictable Bell CUrve Vs. Other Sudden Spiky Curves
- How Cache resolves unnecessary round trip time
- Where should you implement caching?
Strategy 01: Caching at the client app - Drawback: caching data on the client-side means you have to respond to at least one request per client.
Strategy 02: Caching at CloudFront - Caching at the edge is very cost-efficient as it cuts out most of the calls to API Gateway and Lambda.
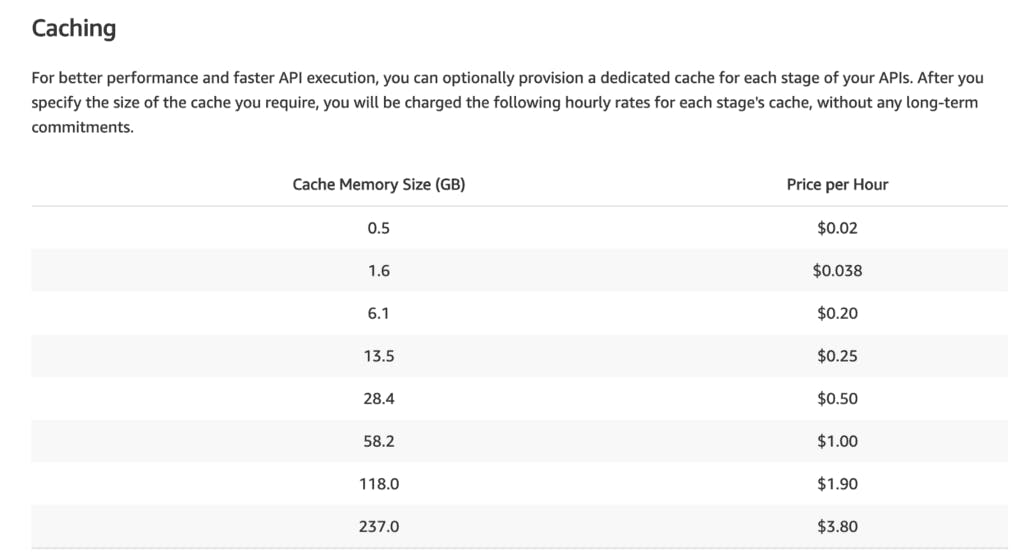
Strategy 03: Caching at API Gateway - gives a lot more control over the cache key; Drawback - you switch from pay-per-use pricing to paying for uptime.
Strategy 04: Caching in the Lambda function - Anything declared outside the handler function is reused between invocations. - Note That: The cached data is only available for that container, Fist call in every container will be a miss... How to resolve it?
- Sharing Cache across all concurrent executions- Usage of ElastiCache and DymanoDB Accelerator (DAX)
Are you implementing caching in every layer of your application!!! Dont forget API Gateway has 29s and AWS Lambda Function has 15min limit.
Never Forget: Lambda will not retry throttled requests from synchronous sources (e.g., API Gateway). It’s important to keep that in mind as you manage concurrency for your functions.
NOTES ON: Concurrency, Invocations, Throttles, Reserved concurrency, Concurrency metrics

1.1 Lambda auto-scales by Traffic but it has limits
- There’s the soft limit of 1000 concurrent executions in most regions. Which you can raise via a support ticket.
- But there’s also a hard limit on how quickly you can increase the concurrent executions after the initial 1000. In most regions, that limit is 500 per minute.
Which means, it’ll take you 18 minutes to reach a peak throughput of 10k concurrent executions.
This is not a problem if your traffic is either very stable or follows the bell curve so there are no sudden spikes.
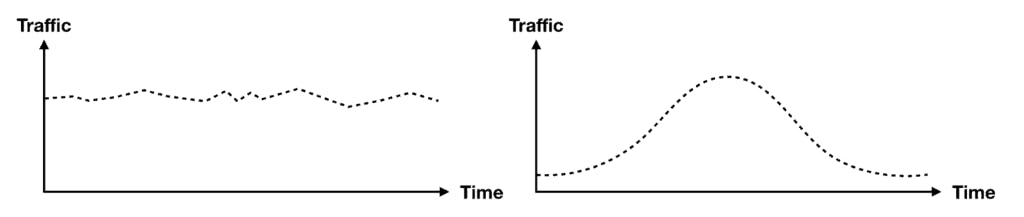
However, if your traffic is very spiky then the 500/min limit will be a problem. For instance, if you provide a streaming service for live events, or you’re in the food ordering business. In both cases, caching needs to be an integral part of your application.
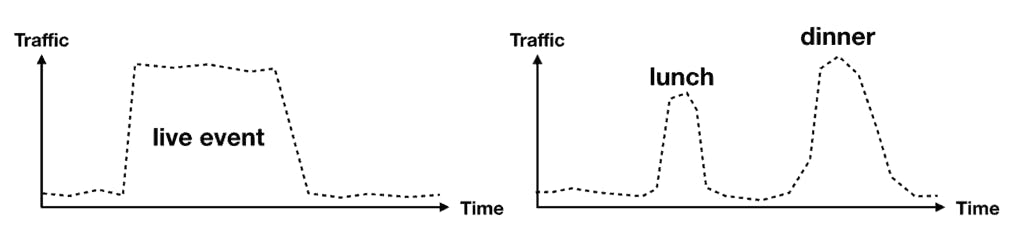
And then there’s the question of performance and cost-efficiency.
Caching improves response time as it cuts out unnecessary roundtrips. In the case of serverless, this also translates to cost savings as most of the technologies we use are pay-per-use.
1.2 Where should you implement caching?
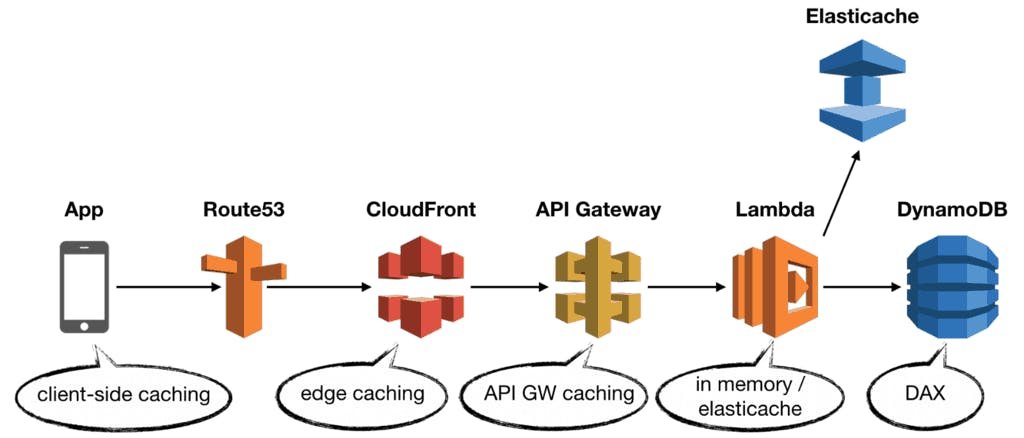
A typical REST API might look like this:
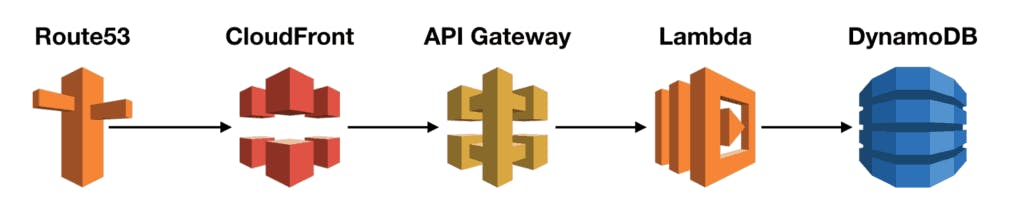
Here you have
- Route53 as the DNS.
- CloudFront as the CDN.
- API Gateway to handle authentication, rate limiting and request validation.
- Lambda to execute business logic.
- DynamoDB as the database.
In this very typical setup, you can implement caching in a number of places.
My general preference is to cache as close to the end-user as possible.
Doing so maximises the cost-saving benefit of your caching strategy.
1.2.1 Caching at the client app
Given the option, I will always enable caching in the web or mobile app itself.
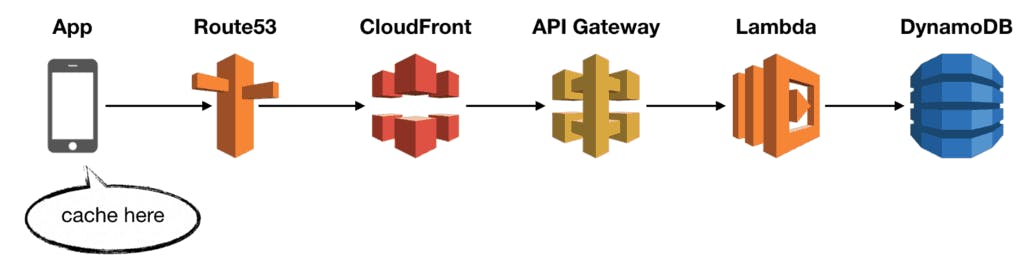
For data that are immutable or seldom change, this is very effective.
For instance, browsers cache images and HTML markups all the time to improve performance. And the HTTP protocol has a rich set of headers to let you finetune the caching behaviour.
Often, client-side caching can be implemented easily using techniques such as memoization and encapsulated into reusable libraries.
Drawback: caching data on the client-side means you have to respond to at least one request per client.
This is still very inefficient, and you should be caching responses on the server-side as well.
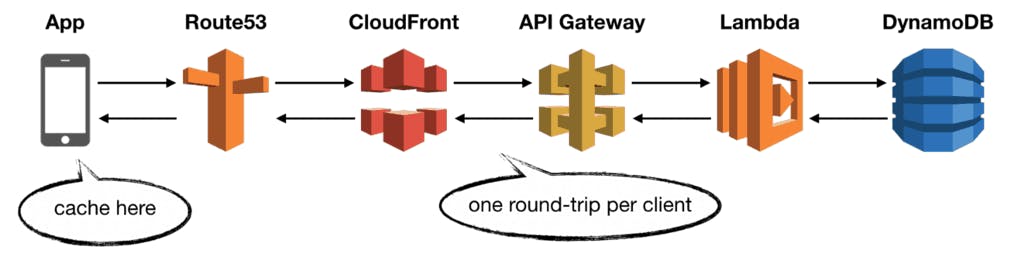
1.2.2 Caching at CloudFront
CloudFront has a built-in caching capability. It’s the first place you should consider caching on the server-side.
Caching at the edge is very cost-efficient as it cuts out most of the calls to API Gateway and Lambda.
Skipping these calls also improve the end-to-end latency and ultimately the user experience. Also, by caching at the edge, you don’t need to modify your application code to enable caching.
CloudFront supports caching by { query strings, cookies and request headers - GET, HEAD and OPTIONS} . It even supports origin failover which can improve system uptime.
In most cases, this is the only server-side caching I need.
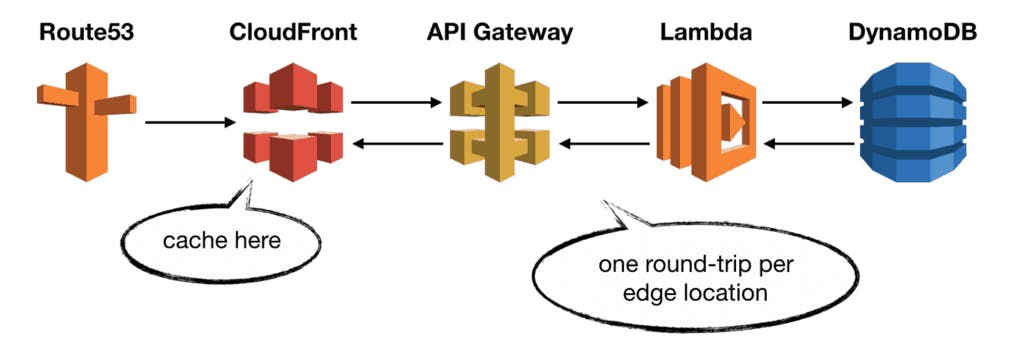
1.2.3 Caching at API Gateway
CloudFront is great, but it too has limitations.
CloudFront only caches responses to GET, HEAD and OPTIONS requests.
If you need to cache other requests then you need to cache responses at API Gateway layer instead.
With API Gateway caching, you can cache responses to any request, including POST, PUT and PATCH. However, this is not enabled by default.

You also have a lot more control over the cache key. For instance, if you have an endpoint with multiple path and/or query string parameters, e.g.
GET /{productId}?shipmentId={shipmentId}&userId={userId}
You can choose which path and query string parameters are included in the cache key. In this case, it’s possible to use only the productId as the cache key.
So all requests to the same product ID would get the cached response, even if shipmentId and userId are different.
One Downside:
One downside to API Gateway caching is that you switch from pay-per-use pricing to paying for uptime. Essentially you’ll be paying for uptime of a Memcached node (that API Gateway manages for you).
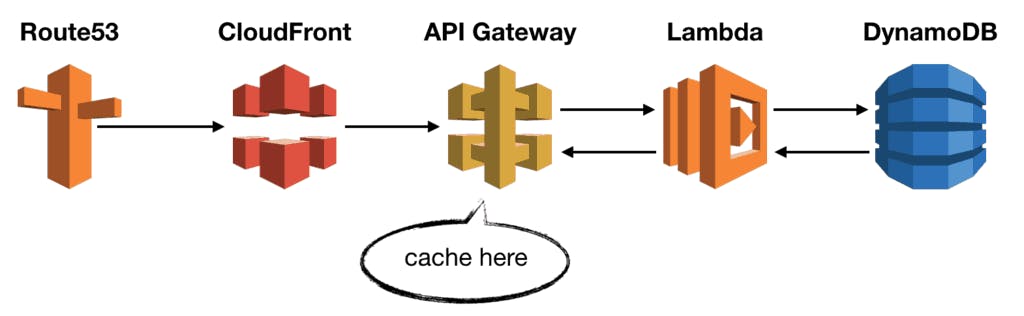
API Gateway caching is powerful, but I find few use cases for it.
The main use case I have is for caching POST requests.
1.2.4 Caching in the Lambda function
You can also cache data in the Lambda function. Anything declared outside the handler function is reused between invocations.
A. Bad Code Example
# These are reused in between invocations
db = os.environ['RDS_DB_NAME’]
user = os.environ['RDS_USERNAME’]
pw_arn = os.environ[‘RDS_PASSWORD_ARN’]
def lambda_handler(event, context):
# Executed on every function invocation
pw = secretsManager.get_secret_value(
SecretId = pw_arn)
conn = openConnection(db, user, pw)
B. Good Code Example
# These are reused in between invocations
db = os.environ['RDS_DB_NAME’]
user = os.environ['RDS_USERNAME’]
pw_arn = os.environ[‘RDS_PASSWORD_ARN’]
pw = secretsManager.get_secret_value(SecretId = pw_arn)
conn = openConnection(db, user, pw)
def lambda_handler(event, context):
print("logics go here")
You can take advantage of the fact that containers are reused where possible and cache any global/static configurations or large objects. This is indeed one of the recommendations from the official best practices guide.

C. Limitations introduced Here
The cached data is only available for that container and there’s no way to share them across all concurrent executions of a function.
This means the overall cache miss can be pretty high – the first call in every container will be a cache miss.
D. How to resolve this limitation - Sharing Cache across all concurrent executions
D1. Solution 01: using Elasticache/Redis
We can cache the data in Elasticache instead. Doing so would allow cached data to be shared across many functions.
But it also requires your functions to be inside a VPC.
- The good news is that the cold start penalty for being inside a VPC will be gone soon.
- The bad news is that you will still be paying for uptime for the Elasticache cluster. Also, introducing Elasticache would require changes to your application code for both reads and writes.
D2. Solution 02: using DynamoDB Accelerator (DAX)
If you use DynamoDB, then there is very little reason to use Elasticache for application-level caching. Instead, you should use DAX.
DAX lets you reap the benefit of Elasticache without having to run it yourself. You do still have to pay for uptime for the cache nodes, but they’re fully managed by DynamoDB.
The great thing about DAX is that it requires a minimal change from your code. But DAX has its own stale!!!
- The main issue I have encountered with DAX is its caching behaviour with regards to query and scan requests.
- In short, queries and scans have their own caches and they’re not invalidated when the item cache is updated. Which means, they can return stale data immediately after an update.
2. Conclusion
To summarise, caching is still an important part of any serverless application. It improves your application’s scalability and performance. It also helps you keep your cost in check even when you have to scale to millions of users.
you can implement caching in every layer of your application.
- As much as possible, you should implement client-side caching and cache API responses at the edge with CloudFront.
- When edge caching is not possible then move the caching further into your application to API Gateway then Lambda or DAX.
- If you’re not using DynamoDB, or you need to cache data that are composed of different data sources then also consider introducing Elasticache.
NOTES
A. Concurrency
The number of requests that your Lambda function serves at any given time is called concurrency.
B. Invocations
The number of times your function code is executed, including successful executions and executions that result in a function error. Invocations aren't recorded if the invocation request is throttled or otherwise resulted in an invocation error. This equals the number of requests billed.
C. Throttles
The number of invocation requests that are throttled. When all function instances are processing requests and no concurrency is available to scale up, Lambda rejects additional requests with TooManyRequestsException. Throttled requests and other invocation errors don't count as Invocations or Errors.
D. Reserved concurrency
The portion of the available pool of concurrent executions that you allocate to one or more functions.
E. Concurrency metrics
Monitoring concurrency can help you manage over provisioned functions and scale your functions to support the flow of application traffic. By default, Lambda provides a pool of 1,000 concurrent executions per region, which are shared by all of your functions in that region.
Lambda also requires the per-region concurrency pool to always have at least 100 available concurrent executions for all of your functions at all times.
Functions can automatically scale instances to manage bursts of traffic, though there is a limit on how many requests can be served during an initial burst.
Once that limit is reached, functions will scale at a rate of 500 instances per minute until they exhaust all available concurrency.
This can come from the per-region 1,000 concurrent executions limit or a function’s reserved concurrency
You can configure reserved concurrency to ensure that functions have enough concurrency to scale—or that they don’t scale out of control and hog the concurrency pool.
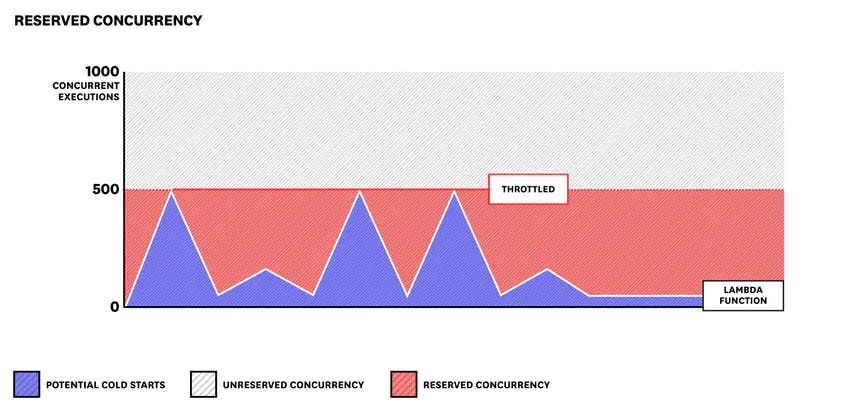
Note that if a function uses all of its reserved concurrency, it cannot access additional concurrency from the unreserved pool. This is especially useful if you know a specific function regularly requires more concurrency than others. You can also reserve concurrency to ensure that a function doesn’t process too many requests and overwhelm a downstream service.
Make sure you only reserve concurrency for your function(s) if it does not impact the performance of your other functions, as it will reduce the size of the available concurrency pool.
Lambda emits the following metrics to help you track concurrency:
| Name | Description | Metric Type | Availability |
| Concurrent executions | The sum of concurrent executions for a function at any point in time | Work: Performance | CloudWatch |
| Unreserved concurrent executions | The total concurrency left available in the pool for functions | Work: Performance | CloudWatch |
| Throttles | The number of throttled invocations caused by invocation rates exceeding concurrent execution limits | Resource: Saturation | CloudWatch |
E1. Metric to alert on: concurrent executions
Functions can execute multiple processes at the same time, or concurrent executions. Monitoring this metric allows you to track when functions are using up all of the concurrency in the pool. You can also create an alert to notify you if this metric reaches a certain threshold.
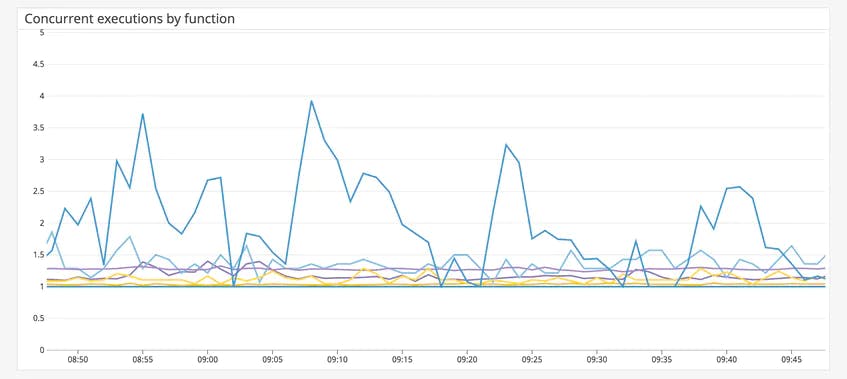
In the example above, you can see a spike in executions for a specific function. As mentioned previously, you can limit concurrent executions for a function by reserving concurrency from the common execution pool. This can be useful if you need to ensure that a function doesn’t process too many requests simultaneously.
E2. Metric to watch: unreserved concurrent executions
You can also track unreserved concurrent executions, equivalent to the total number of available concurrent executions for your account. If you reserved concurrency for any of your functions then this metric would equal the:
total available concurrent executions - any reserved concurrency.
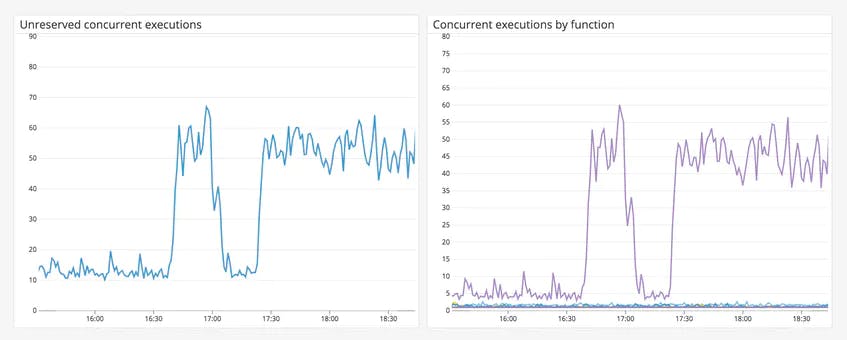
The graphs above show a spike in unreserved concurrency and one function using most of the available concurrency. This could be due to an upstream service sending too many requests to the function. In order to ensure that other functions have enough concurrency to operate efficiently, you can reserve concurrency for this function.
However, keep in mind that Lambda will throttle the function if it uses all of its reserved concurrency.
E3. Metric to alert on: throttles
As requests come in, your function will scale to meet demand, either by pulling from the unreserved concurrency pool (if it does not have any reserved concurrency) or from its reserved concurrency pool (if available).
- Once the pool is exhausted, Lambda will start throttling all functions in that region and reject all incoming requests.
- You should alert on function throttles so that you can proactively monitor capacity and the efficiency of your functions.
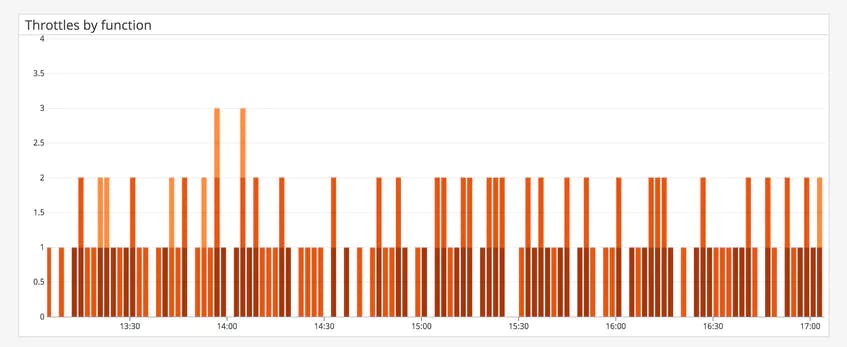
Constant throttling could indicate that there are more requests than your functions can handle and that there is not enough capacity for your functions. What to do to resolve it?
- If you have a function that is critical for your application, you can assign reserved concurrency for it. This will help ensure that your function will have enough concurrent executions to handle incoming requests.
it will meantime limit show many requests it processes.
- If you are consistently exhausting the concurrency pool, you can request an increase to the per-region concurrent executions limit in your account.
Depending on how the function was invoked, Lambda will handle failures from throttles differently. For example, Lambda will not retry throttled requests from synchronous sources (e.g., API Gateway). It’s important to keep that in mind as you manage concurrency for your functions.