
ServerlessArchitecture#07 - Leveraging Lambda Cache for Serverless Cost-Efficiency : An alternative to external caches such as Redis or Memcache
An Oversimplification of Lambda Cache Problem


Cost-efficiency is one of the main pillars of the Serverless Well-Architected framework. Read-intensive applications can save money and improve efficiency by using Lambda cache systems. AWS Lambda’s internal memory could be used as a caching mechanism.
Also, it’s worth paying attention to the fact that AWS charges for Lambda execution in increments of 100ms. So, if the average execution time for your function is 110ms, it will charge you for 200ms. So increasing memory and bringing execution time down to below 100ms can deliver a worthwhile cost saving.

To summarize, the blog Use-Cases are:
- Do You Know!!! - A Lambda container remains alive after an invocation is served, even if it stays idle for some time.
- How to use the Lambda Function's internal memory instead of ElastiCache/Redis and Memcache (in DAX) Note: ElastiCache and Memcache will lead you PAY-BY-UPTIME model instead of PAY-AS-YOU-GO to keep those service instance running all the time for cache management.
- Basic structure of a Lambda function and Caching data outside Lambda handler
- Considerations for Lambda caching
Consideration A: Using CloudFront with API Gateway
Consideration B: Cache Available = How much memory does the Lambda function need - how much is allocated
Consideration C: Lambda cache might end up having to hit the database most of the time in practice
NOTE A: Scalability and Concurrency
A1. After an initial burst of traffic, Lambda can scale up every minute by an additional 500 microVMs (or instances of a function).
A2. Always Remember: Lambda doesn’t limit the number of “requests per second or minute“, Concurrency Limits and Scalability: 500 to 3000
A3. Try to stay below double-digit milliseconds.
NOTE B: Security Considerations
B1. Reserved concurrency setting is recommended to be used whenever possible

A Lambda container remains alive after an invocation is served, even if it stays idle for some time. Whatever was loaded in the container’s memory will remain there for the next invocations.
And that can be used as a caching mechanism as we demonstrate below. In some cases, this could be an alternative to external caches such as Redis or Memcached.
Last in the First
1.1 Basic structure of a Lambda function
The basic structure of a Lambda function is the main file containing a handler function:
import json
def lambda_handler(event, context):
# TODO implement
return {
'statusCode': 200,
'body': json.dumps('Hello from Me - Lambda - The JaRotBall!')
}
What runs inside the lambda_handler function is lost after the execution ends, but what is loaded outside the handler function will remain in memory as long as the container is alive.
Consider a read-intensive backend service that provides data about application users. It receives a username as an argument, looks for the user in a database, and returns the information to the requester.
import json
import users_database
def lambda_handler(event, context):
# TODO implement
username = event['username']
user = users_database.get(username=username)
return {
'statusCode': 200,
'body': json.dumps('Hello from Me - Lambda - The JaRotBal!')
}
1.2 Caching data outside Lambda handler
The basic idea of using Lambda for caching is to start keeping this information in memory, outside the handler function. We could delegate the user data collection to a caching mechanism that would be loaded outside the handler function.
import json
import cache
def lambda_handler(event, context):
# TODO implement
username = event['username']
user = cache.get_user(username=username)
return {
'statusCode': 200,
'body': json.dumps('Hello from Me - Lambda - The JaRotBal!')
}
Whenever user information is needed, we ask the cache. If the username is not available, the cache automatically pulls it from the database and updates its own internal buffer. In future invocations, when the same username is requested, the cache won’t have to query the database again.
import json
import users_database
cache_by_username={} // this will be available in cache during the further invocations
def get_user(*,username):
# Get user data if cache missed
if username not in cache_by_username:
cache_by_username[username] = users_database.get(username=username)
return cache_by_username[username]
The cache_by_username variable is a key-value map. Everything loaded there will remain in memory throughout the Lambda container lifecycle.
In subsequent requests, retrieving cached user data will not only be faster but also cheaper, since we won’t have to hit the database.
2. Considerations for Lambda caching
The above is obviously an oversimplification of the problem. We would likely need to consider some other factors to make sure our caching works properly.
| Considerations | Description |
| A. Using CloudFront with API Gateway To avoid request reaching to Lambda Function | In the example above, the function isn’t really doing anything with the cached data other than returning it. - In these cases, we could cache in a higher-level part of the infrastructure by using CloudFront with API Gateway - This would avoid requests from even reaching the Lambda function. |
| B. How much left for Caching | Another aspect is cache size and resource usage - Cache Available = How much memory does the Lambda function need - how much is allocated - If the Lambda cache starts to grow further, it may cause memory exhaustion errors and prevent the function from working altogether. - run a benchmark and avoid this potential failure point |
| C. Worst Scenario Lambda cache might end up having to hit the database most of the time in practice | - Another thing to consider is the lack of synchronization between Lambda containers. - When multiple invocations are running concurrently, Lambda has to spin up one container for each. - They will not have the exact same usernames in their caches, as invocation arguments hitting each container will hardly be the same. And this could lead to the below Dilemma. |
Dilemma: For that reason in Consideration C, we can’t ensure consistent caching performance across all Lambda invocations. Depending on the number of concurrent requests and the variability of usernames requested, the Lambda cache might end up having to hit the database most of the time in practice.
Scalability and Concurrency
A Lambda function’s concurrency level is the number of invocations being served simultaneously at any given point in time.
Lambda doesn’t limit the number of “requests per second or minute“,
For example, as is common in API services, Developers can run as many requests per period of time as needed, providing that it doesn’t violates concurrency limits.
What is Concurrency?
As stated below, concurrency is the total number of simultaneous requests in a given time. Below is a visual representation of this concept, to make it easier to understand.
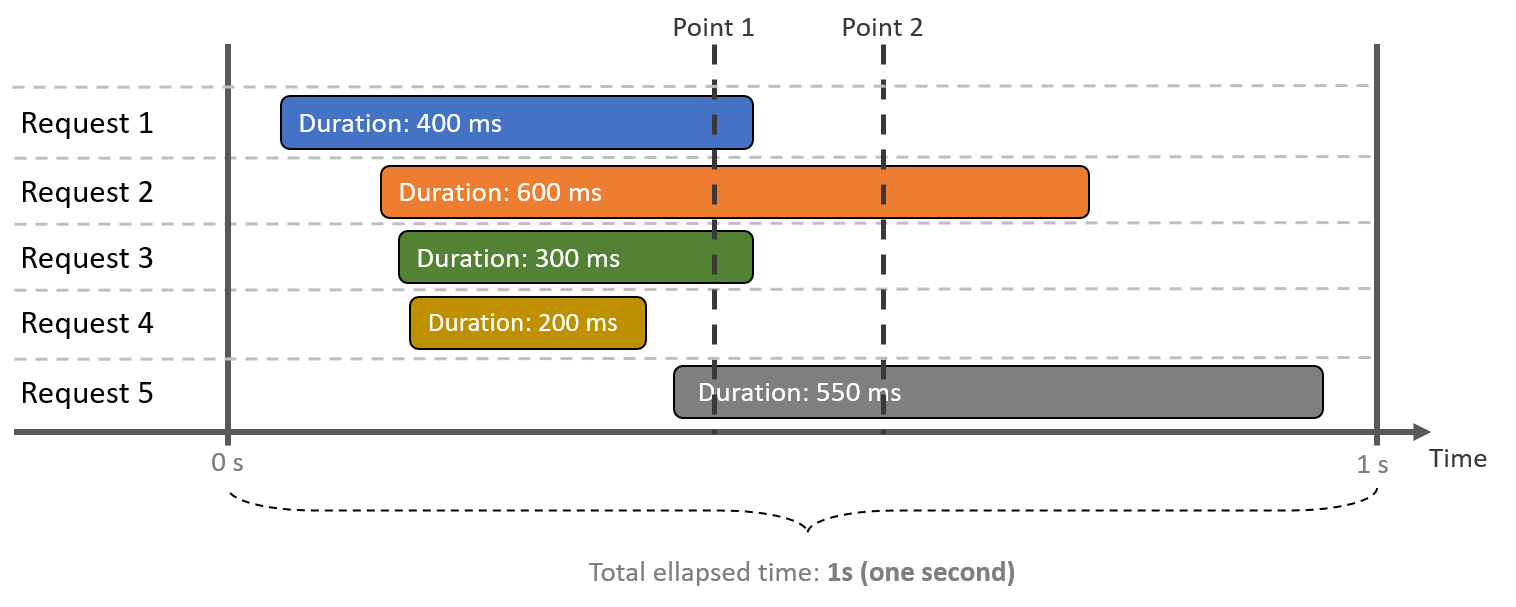
Key takeaways from the diagram above:
- All requests lasted a few milliseconds, having started and finished within one second
- At time Point 1, the concurrency is four requests
- At time Point 2, concurrency dropped to only two requests
- Despite handling five requests in total, the maximum concurrency was four over this period of one second
Concurrency Limits and Scalability
Lambda concurrency limits will depend on the Region where the function is deployed. It will vary from 500 to 3,000.
New functions are limited to this default concurrency threshold set by Lambda.
After an initial burst of traffic, Lambda can scale up every minute by an additional 500 microVMs (or instances of a function).
This scaling process continues until the concurrency limit is met. Developers can request a concurrency increase in the AWS Support Center.
When Lambda is not able to cope with the amount of concurrent requests an application is experiencing, requesters will receive a throttling error (429 HTTP status code).
Provisioned Concurrency
AWS Lambda allows developers to anticipate how many instances of a function should be provisioned and warm to serve requests.
By setting a minimal provisioned concurrency level, the performance of all requests are guaranteed to
"Stay below double-digit milliseconds."
Using this feature can be beneficial for workloads that are time-sensitive, such as customer-facing endpoints. Never mind, it is a step back in the serverless model and comes with several financial caveats.