
ServerlessArchitecture#10 - AWS Optimization Best Practice #Part-02: Lazy Initialization


Lazy Initialization Example (Python & boto3)
It is a known fact that outsourcing your services to the cloud brings a lot of benefits such as reduced operational activity and almost unlimited and on-demand resources. However, those benefits come with additional billing costs which can increase dramatically if not enough attention is paid to it. One way to reduce the cost of cloud infrastructure is by making the software that runs on top of it intelligent and efficient. There is a plethora of design patterns which - when applied to our software designs - can result in a better utilization of hardware resources. One of such design patterns is called Lazy Loading and in this technical focused section, I will examine an approach on how to create a Lambda which utilizes that technique. Lets see a Lazy loading example in Python.
import boto3
S3_client = None
ddb_client = None
def get_objects(event, context):
if not s3_client:
s3_client = boto3.client("s3")
# business logic
def get_items(event, context):
if not ddb_client:
ddb_client = boto3.client(”dynamodb")
# business logic
To summarize, the blog Use-Cases are:
- Lazy initialization: a Python with Boto3 example
- My client stroy how to read the object stream into chunks
- Traffic peaks might cause the AWS to my Lambda with a RunTimeExceptionError.
- What is Lazy loading?
- Why Lazy loading is importent: consider the lambda pricing model.
- Note: optimizing your functions to require less memory and run faster, results into reducing your bill.
- Implementing Lazy loading in Python
A. Get the response returned by object after uploading to S3 bucket
B. Get the Stream from Response Body using response['Body'], but in chunks for more memory efficiency: Open the stream using TextIOWrapper()
C. Read the data from the Stream using For-Loop and filter the logs for HTTP 460 responses
- Comparison results: Is My Lambda Smarter Now
- Note: From a technical perspective, it’s preferred to read the contents of file objects using Generators instead of dumping everything into memory

Refresher: From Where your Lamda Codes are Loaded
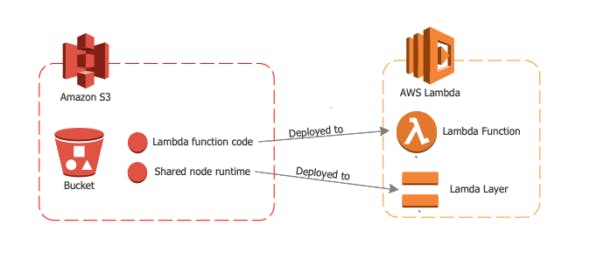
1. Lets Start with a Client Story
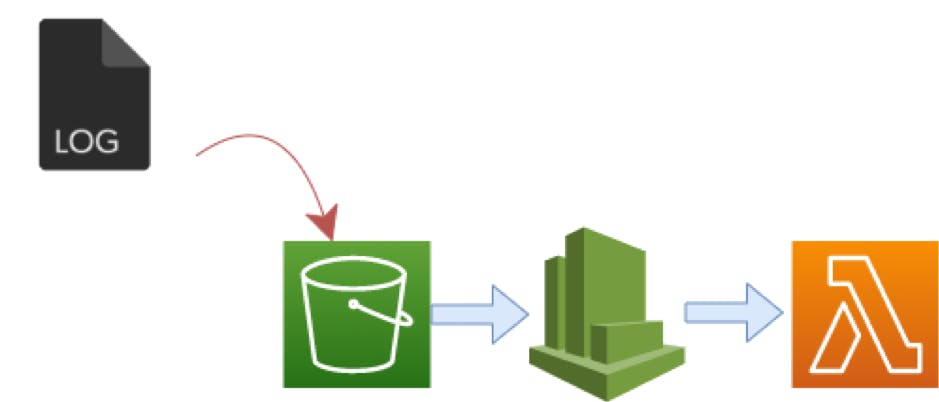
One of our client’s implementations contained a Lambda with 128MB memory allocated to it. In our case,
- Whenever a new object is stored in S3,
- it creates a CloudWatch event which triggers our Lambda.
- The lambda function read the object stream and
- Finally converts the logs into a UTF-8 string while keeping copies of both forms in memory in chunks for better memory efficiency.
This specific function was operating fine under normal conditions. However, during traffic peaks I noticed that it was
Being killed by AWS with a RuntimeExceptionError.
Looking further into the Logs using CloudWatch, I discovered that it was trying to consume 129MB of memory which was the tipping point.
Instead of just increasing the memory allocated to that Lambda, I decided to investigate how I could make it smarter and more efficient using the Lazy loading approach.
NOTES:
==========================================================
What is Lazy loading?
Lazy loading is a technique in which the initialization of an object is being held off until the data of the object is needed in the program. In other words, during execution, a program should keep in memory only the data that is necessary for the commands it executes just like the above code snippet.
Why this is important?
According to the pricing model, not taking into account any side calls, whenever a Lambda is executed,
You are charged for the number of requests and the duration.
However, the price tier depends on the amount of memory the Lambda uses during its execution. This means that when the memory tier is higher, the pricing tier for the Lambda is also higher.
So, optimizing your functions to require less memory and run faster, results into reducing your bill.
2.1 Implementing Lazy loading in Python
The event variable contains all the necessary data and is passed into the handler function. All we need to do is extract that information from the dictionary.
A. Get the response returned by object after uploading to S3 bucket
Get the object
======================================================
def lambda_handler(event, context):
s3 = boto3.client('s3')
source_bucket_name = event['Records'][0]['s3']['bucket']['name']
key_name = event['Records'][0]['s3']['object']['key']
response = s3.get_object(Bucket=source_bucket_name, Key=key_name)
.get_object() Request Syntax
======================================================
response = client.get_object(
Bucket='string',
IfMatch='string',
IfModifiedSince=datetime(2015, 1, 1),
IfNoneMatch='string',
IfUnmodifiedSince=datetime(2015, 1, 1),
Key='string',
Range='string',
ResponseCacheControl='string',
ResponseContentDisposition='string',
ResponseContentEncoding='string',
ResponseContentLanguage='string',
ResponseContentType='string',
ResponseExpires=datetime(2015, 1, 1),
VersionId='string',
SSECustomerAlgorithm='string',
SSECustomerKey='string',
RequestPayer='requester',
PartNumber=123,
ExpectedBucketOwner='string'
)
.get_object() Response Syntax
======================================================
{
'Body': StreamingBody(),
'DeleteMarker': True|False,
'AcceptRanges': 'string',
'Expiration': 'string',
'Restore': 'string',
'LastModified': datetime(2015, 1, 1),
'ContentLength': 123,
'ETag': 'string',
'MissingMeta': 123,
'VersionId': 'string',
'CacheControl': 'string',
'ContentDisposition': 'string',
'ContentEncoding': 'string',
'ContentLanguage': 'string',
'ContentRange': 'string',
'ContentType': 'string',
'Expires': datetime(2015, 1, 1),
'WebsiteRedirectLocation': 'string',
'ServerSideEncryption': 'AES256'|'aws:kms',
'Metadata': {
'string': 'string'
},
'SSECustomerAlgorithm': 'string',
'SSECustomerKeyMD5': 'string',
'SSEKMSKeyId': 'string',
'BucketKeyEnabled': True|False,
'StorageClass': 'STANDARD'|'REDUCED_REDUNDANCY'|'STANDARD_IA'|'ONEZONE_IA'|'INTELLIGENT_TIERING'|'GLACIER'|'DEEP_ARCHIVE'|'OUTPOSTS',
'RequestCharged': 'requester',
'ReplicationStatus': 'COMPLETE'|'PENDING'|'FAILED'|'REPLICA',
'PartsCount': 123,
'TagCount': 123,
'ObjectLockMode': 'GOVERNANCE'|'COMPLIANCE',
'ObjectLockRetainUntilDate': datetime(2015, 1, 1),
'ObjectLockLegalHoldStatus': 'ON'|'OFF'
}
B. Get the Stream from Response Body using response['Body'], but in chunks for more memory efficiency: Open the stream using TextIOWrapper()
The get_object() returns a dictionary which contains metadata related to the object that was just added into S3. The response[“Body”] allows us to open a stream to that object. A stream is a file-like object which allows us to read data from the object.
Refresher: What is a Stream ?
A stream is a file-like object which allows us to read data from the object.
Having created the stream to the object, we finally open it in binary mode rb and decode it into a UTF-8 string by wrapping the gzip.GzipFile() into the TextIOWrapper().
TextIOWrapper() not only allows us to read the stream into a string but also does it in an efficient way by decoding it in chunks thus making our program more efficient in terms of memory consumption and execution time.
def lambda_handler(event, context):
s3 = boto3.client('s3')
source_bucket_name = event['Records'][0]['s3']['bucket']['name']
key_name = event['Records'][0]['s3']['object']['key']
response = s3.get_object(Bucket=source_bucket_name, Key=key_name)
# Open the stream in binary mode [objects in s3 are binary]
# TextIOWrapper decodes in chunks.
stream_content = io.TextIOWrapper(gzip.GzipFile(None, 'rb', fileobj=response['Body']))
C. Read the data from the Stream using For-Loop and filter the logs for HTTP 460 responses
At this point, we read the data from the stream with a simple “for loop”. The specific Lambda function was trying to filter the logs for HTTP 460 responses.
def lambda_handler(event, context):
s3 = boto3.client('s3')
source_bucket_name = event['Records'][0]['s3']['bucket']['name']
key_name = event['Records'][0]['s3']['object']['key']
response = s3.get_object(Bucket=source_bucket_name, Key=key_name)
stream_content = io.TextIOWrapper(gzip.GzipFile(None, 'rb', fileobj=response['Body']))
# Count HTTP 460s per targetgroup in AWS ELB [dict]
http_460s_per_targetgroup = {}
for each_line in stream_content:
if (" 460 " in each_line) and ("targetgroup" in each_line):
# Do some regex magic to find "targetgroup"
targetgroup_name =\
return_target_group_from_string(each_line)
increment_targetgroup_460_counter(\
http_460s_per_targetgroup,\
targetgroup_name)
else:
logging.info("False HTTP 460 log does not contain a target group")
3. Comparison results: Is My Lambda Smarter Now
By making the Lambda smarter, I noticed a big difference in its execution time. I’ll let you figure out where the change in the code was applied ;)

Unfortunately, CloudWatch does not have memory consumption charts and so, I could only pull out several log messages. Moreover, the retention period for the logs was configured to 7 days, so these are the last logs I could find. I had to remove the info messages.

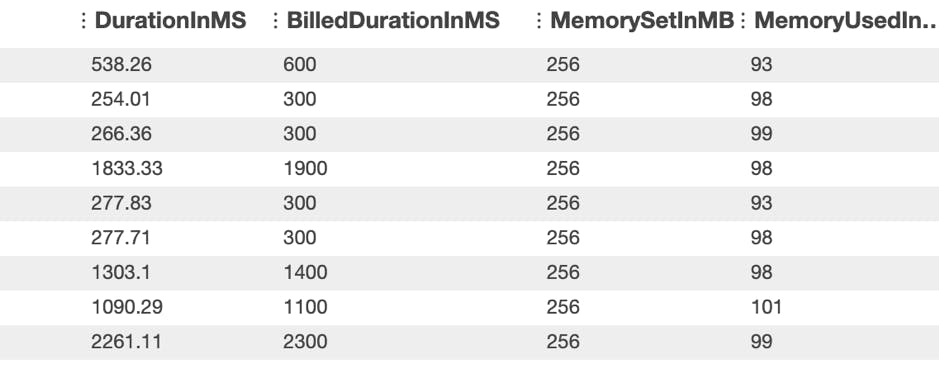
To make sure that the new function is safe, I doubled the amount of memory (265MB) it had initially allocated. This is a safe measure I believe was logical to prevent it from failing.
4. Conclusion
There are multiple blogposts and guides online which describe how to read/write data from/to an object in S3 bucket. However, only a few describe how you can make your functions more efficient.
In my case, improving the Lambda probably didn’t save a lot of cost, however, if implemented at scale or in a serverless environment, it can result in a substantial cost reduction and also make the system faster.